近期,中科院自动化所提出了全 球首 个图文音(视觉-文本-语音)三模态预训练模型。同时具备跨模态理解与跨模态生成能力。该模型不仅可实现跨模态理解(比如图像识别、语音识别等任务),也能完成跨模态生成(比如从文本生成图像、从图像生成文本、语音生成图像等任务)。
模型是通过主观意识借助实体或者虚拟表现,构成客观阐述形态结构的一种表达目的的物件(物件并不等于物体,不局限于实体与虚拟、不限于平面与立体)。模型构成形式分为实体模型(拥有体积及重量的物理形态概念实体物件)及虚拟模型(用电子数据通过数字表现形式构成的形体以及其他实效性表现)。
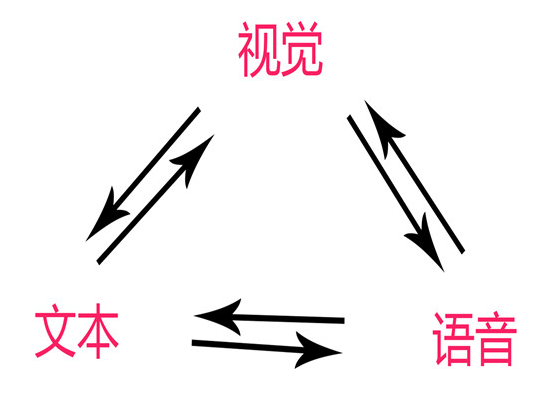
三模态预训练模型的提出将改变当前单一模型对应单一任务的人工智研发范式,三模态图文音的统一语义表达将大幅提升文本、语音、图像和视频等领域的基础任务性能,并在多模态内容的理解、搜索、推荐和问答,语音识别和合成,人机交互和无人驾驶等商业应用中具有潜力巨大的市场价值。“大数据+大模型+多模态”多任务统一学习将引领技术发展的潮流。
延伸阅读:
图像识别是利用计算机对图像进行处理、分析和理解,以识别各种不同模式的目标和对象的技术,是应用深度学习算法的一种实践应用。现阶段图像识别技术一般分为人脸识别与商品识别,人脸识别主要运用在安全检查、身份核验与移动支付中;商品识别主要运用在商品流通过程中,特别是无人货架、智能零售柜等无人零售领域。
图像的传统识别流程分为四个步骤:图像采集→图像预处理→特征提取→图像识别。图像识别软件国外代表的有康耐视等,国内代表的有图智能、海深科技等。另外在地理学中指将遥感图像进行分类的技术。图形刺激作用于感觉器官,人们辨认出它是经验过的某一图形的过程,也叫图像再认。在图像识别中,既要有当时进入感官的信息,也要有记忆中存储的信息。只有通过存储的信息与当前的信息进行比较的加工过程,才能实现对图像的再认。
图像识别可能是以图像的主要特征为基础的。每个图像都有它的特征,如字母A有个尖,P有个圈、而Y的中心有个锐角等。对图像识别时眼动的研究表明,视线总是集中在图像的主要特征上,也就是集中在图像轮廓曲度最大或轮廓方向突然改变的地方,这些地方的信息量最大。而且眼睛的扫描路线也总是依次从一个特征转到另一个特征上。由此可见,在图像识别过程中,知觉机制必须排除输入的多余信息,抽出关键的信息。同时,在大脑里必定有一个负责整合信息的机制,它能把分阶段获得的信息整理成一个完整的知觉映象。
图像识别是人工智能的一个重要领域。为了编制模拟人类图像识别活动的计算机程序,人们提出了不同的图像识别模型。例如模板匹配模型。这种模型认为,识别某个图像,必须在过去的经验中有这个图像的记忆模式,又叫模板。当前的刺激如果能与大脑中的模板相匹配,这个图像也就被识别了。例如有一个字母A,如果在脑中有个A模板,字母A的大小、方位、形状都与这个A模板完全一致,字母A就被识别了。这个模型简单明了,也容易得到实际应用。但这种模型强调图像必须与脑中的模板完全符合才能加以识别,而事实上人不仅能识别与脑中的模板完全一致的图像,也能识别与模板不完全一致的图像。例如,人们不仅能识别某一个具体的字母A,也能识别印刷体的、手写体的、方向不正、大小不同的各种字母A。同时,人能识别的图像是大量的,如果所识别的每一个图像在脑中都有一个相应的模板,也是不可能的。
语音识别是一门交叉学科。近二十年来,语音识别技术取得显着进步,开始从实验室走向市场。人们预计,未来10年内,语音识别技术将进入工业、家电、通信、汽车电子、医疗、家庭服务、消费电子产品等各个领域。 语音识别听写机在一些领域的应用被美国新闻界评为1997年计算机发展十件大事之一。很多专家都认为语音识别技术是2000年至2010年间信息技术领域十大重要的科技发展技术之一。 语音识别技术所涉及的领域包括:信号处理、模式识别、概率论和信息论、发声机理和听觉机理、人工智能等等。
与机器进行语音交流,让机器明白你说什么,这是人们长期以来梦寐以求的事情。中国物联网校企联盟形象得把语音识别比做为“机器的听觉系统”。语音识别技术就是让机器通过识别和理解过程把语音信号转变为相应的文本或命令的高技术。 语音识别技术主要包括特征提取技术、模式匹配准则及模型训练技术三个方面。语音识别技术车联网也得到了充分的引用,例如在翼卡车联网中,只需按一键通客服人员口述即可设置目的地直接导航,安全、便捷。
根据识别的对象不同,语音识别任务大体可分为3类,即孤立词识别(isolated word recognition),关键词识别(或称关键词检出,keyword spotting)和连续语音识别。其中,孤立词识别 的任务是识别事先已知的孤立的词,如“开机”、“关机”等;连续语音识别的任务则是识别任意的连续语音,如一个句子或一段话;连续语音流中的关键词检测针对的是连续语音,但它并不识别全部文字,而只是检测已知的若干关键词在何处出现,如在一段话中检测“计算机”、“世界”这两个词。
根据针对的发音人,可以把语音识别技术分为特定人语音识别和非特定人语音识别,前者只能识别一个或几个人的语音,而后者则可以被任何人使用。显然,非特定人语音识别系统更符合实际需要,但它要比针对特定人的识别困难得多。
另外,根据语音设备和通道,可以分为桌面(PC)语音识别、电话语音识别和嵌入式设备(手机、PDA等)语音识别。不同的采集通道会使人的发音的声学特性发生变形,因此需要构造各自的识别系统。
语音识别的应用领域非常广泛,常见的应用系统有:语音输入系统,相对于键盘输入方法,它更符合人的日常习惯,也更自然、更高效;语音控制系统,即用语音来控制设备的运行,相对于手动控制来说更加快捷、方便,可以用在诸如工业控制、语音拨号系统、智能家电、声控智能玩具等许多领域;智能对话查询系统,根据客户的语音进行操作,为用户提供自然、友好的数据库检索服务,例如家庭服务、宾馆服务、旅行社服务系统、订票系统、医疗服务、银行服务、股票查询服务等等。
新闻来源:中科院自动化所