大家好,今天小编给大家分享一下Flume的面试点,按照这个回答,面试官会吐血,哈哈!
01 Flume起源
Flume最早是Cloudera开发的实时日志收集系统,最早的时候Flume的版本称为Flume OG(original generation),随着功能的扩展和代码的重构,随之出现了我们熟知的Flume NG(next generation),后来也捐给了Apache基金会成为了Apache的顶级项目。Apache Flume 是一个分布式、高可靠(事务)、高可用(failover)的用来收集、聚合、转移不同来源的大量日志数据到中央数据仓库的工具。

02 Flume架构
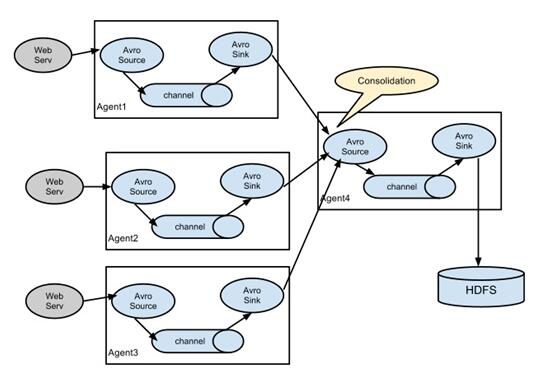
Event:Flume定义的一个数据流传输的最小单元,数据被封装到Event中往后传输。Event由Header和Byte Payload组成:
Header:一系列可选的string属性(键值对Map)Byte Payload:装载数据的字节数组(网络传输都是传输字节)
Agent:Flume最小的独立运行单位,一个Agent就是一个Flume的实例,本质是一个JVM进程,该JVM进程控制Event数据流从外部日志生产者那里传输到目的地(或者是下一个Agent)。同时,一个Agent就对应一个配置文件。
Source:对接输入源,监控外部数据源的数据,传输给Channel。
Source类型:
支持Avro(RPC)协议监控指定目录内数据变更(上传文件)监控某个端口,将流经端口的每一个文本行数据作为Event输入监控消息队列数据Channel:简单理解,就是缓存数据。
Channel类型:
Memory Channel:内存中队列,适用于不需要关心数据丢失的情景File Channel:将所有Event写到磁盘,在程序关闭或机器宕机的情况下不会丢失数据Kafka channel :直接使用消息队列作为数据缓存Sink:我们采集数据的目的地,Sink不断地轮询Channel中的Event且批量地移除它们,并将这些Event批量写入到存储系统或者发送到另一个Agent。
Sink类型:
HDFS:数据写入到HDFSAvro:数据被转换成Avro event,然后发送到配置的RPC端口上(Avro Source)File Roll:存储数据到本地文件系统Hbase:数据写入Hbase数据库Logger:数据写入到日志文件(往往是写到控制台)

03 Flume事务流程

Channel使用被动存储机制,依靠Source完成数据写入(推送)、依靠Sink完成数据读取(拉取)。
Channel是Event队列,先进先出:Source -> EventN,...,Event2,Event1 -> SinkSink是完全事务性的。在从Channel批量删除数据之前,每个Sink用Channel启动一个事务。批量Event一旦成功写出到存储系统或下一个Agent,Sink就利用Channel提交事务。事务一旦被提交,该Channel从自己的内部缓冲区删除Event
Flume 推送事务流程
doPut:将批数据先写入临时缓冲区putList,不是来一条Event就处理,是来一批Event才处理doCommit:检查Channel内存队列空间是否充足,充足则直接写入Channel内存队列,不足则doRollback回滚数据到putList,等待重新传递,回滚数据指的是putList的Event索引回退到之前
Flume拉取事务流程
doTake:先将数据取到临时缓冲区takeListdoCommit:如果数据全部发送成功,则清除临时缓冲区takeListdoRollback:数据发送过程中如果出现异常,将临时缓冲区takeList中的数据doRollback归还给Channel内存队列,等待重新传递

04 Flume参数调优

Source
1、增加Source个数,可以增大Source读取数据的能力。例如:当某一个目录产生的文件过多时需要将这个文件目录拆分成多个文件目录,同时配置好多个 Source以保证Source有足够的能力获取到新产生的数据。
2、适当调大batchSize,可以提高Source搬运Event到Channel时的性能。
Channel
1、type选择memory时Channel的性能最好,但是如果Flume进程意外挂掉可能会丢失数据。
2、type选择file时Channel的容错性更好,但是性能上会比memory Channel差。使用file Channel时 dataDirs配置多个不同盘下的目录(注意不是同一个盘不同目录哦)可以提高性能。3、capacity参数决定Channel可容纳最大的Event条数。
Sink
1、增加Sink的个数可以增加Sink消费Event的能力。Sink也不是越多越好够用就行,过多的Sink会占用系统资源,造成系统资源不必要的浪费。
2、适当调大batchSize,可以提高Sink从Channel搬出Event的性能。

05 Flume的一个bug插曲
有一次我使用file作为channel重启时候碰见一个错误,长这样:
ERROR org.apache.flume.SinkRunner: Unable to deliver event. Exception follows.java.lang.IllegalStateException: Channel closed [channel=fileChannel]. Due to java.io.EOFException: null at org.apache.flume.channel.file.FileChannel.createTransaction(FileChannel.java:340) at org.apache.flume.channel.BasicChannelSemantics.getTransaction(BasicChannelSemantics.java:122) at org.apache.flume.sink.hdfs.HDFSEventSink.process(HDFSEventSink.java:368) at org.apache.flume.sink.DefaultSinkProcessor.process(DefaultSinkProcessor.java:68) at org.apache.flume.SinkRunner$PollingRunner.run(SinkRunner.java:147) at java.lang.Thread.run(Thread.java:745)Caused by: java.io.EOFException at java.io.RandomAccessFile.readInt(RandomAccessFile.java:827) at java.io.RandomAccessFile.readLong(RandomAccessFile.java:860) at org.apache.flume.channel.file.EventQueueBackingStoreFactory.get(EventQueueBackingStoreFactory.java:80) at org.apache.flume.channel.file.Log.replay(Log.java:426) at org.apache.flume.channel.file.FileChannel.start(FileChannel.java:290) at org.apache.flume.lifecycle.LifecycleSupervisor$MonitorRunnable.run(LifecycleSupervisor.java:251) at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:471) at java.util.concurrent.FutureTask.runAndReset(FutureTask.java:304) at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$301(ScheduledThreadPoolExecutor.java:178) at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:293) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615) ... 1 mor